
The science behind ML Alpha’s AI Scores
In this article, we offer transparency and insights into the science behind ML Alpha’s AI Scores that power the Radar Charts featured across our website. These charts serve as visual representations of our sophisticated Machine Learning (ML) algorithms, providing users with valuable insights into various aspects of stock performance potential according to different criteria. From short-term projections to dividend potential and safety scores, our ML Alpha scores are meticulously calculated to aid investors in making purely data-driven informed decisions.
The ML Alpha radar chart is composed of the short, mid and long term performance potential score, dividend potential score and Safety score.

Here is how the scores can be interpreted:
Short Term: A high short-term score indicates that the ML algorithms predict the company’s stock price is more likely to perform well over the next 2-Weeks to 1-Month period.
Mid Term: A high mid-term score indicates that the ML algorithms predict the company’s stock price is more likely to perform well over the next 1-Quarter to 1-Year period.
Long Term: A high long-term score indicates that the ML algorithms predict the company’s stock price is more likely to perform well over the next 1-Year to 3-Year period.
Dividend: A high dividend score indicates that the ML algorithms predict the company is likely to pay out a high dividend yield over the next year.
Safety: A high safety score indicates that the ML algorithms predict the company is likely to be less volatile and has lower risks of losing its value over the next year
An empty ML Alpha Score chart means that the necessary data for the ML models to process and produce a score was not available or the data didn’t have enough quality for that company at that point in time.
How do I use the ML Alpha AI Scores?
The scores can be used to compare different companies and identify those that are predicted to perform better in different timeframes and according to different criteria. They can be used to build portfolios tailored to your investment goals and desired rebalance frequency.
These scores are solely derived from predictions generated by multiple ML models, which analyze hundreds of fundamental, technical, and contextual parameters for each company at a specific point in time. However, it’s important to note that a high AI Score for a particular stock does not guarantee performance. The predictions provided by the ML models, and consequently the AI Scores, are inherently statistical in nature. Therefore, there is no assurance that any given company will perform well in the future.
To enhance the likelihood of success, it is not advisable to rely solely on individual stock selection. Instead, diversifying the portfolio with multiple stocks (e.g., 10 or more) that exhibit top scores across your investment criteria can help mitigate risks and improve overall performance.
To select 10 or more stocks for your portfolio, you can utilize the Performance Criteria Selection bars to tailor them to your investment goals.
For example, if you aim to maximize the potential returns of your portfolio (without prioritizing safety) and are prepared to rebalance it every 2 weeks to 1 month, then you should establish the following goals in the AI Top Picks section or your new Portfolio.

Screenshot of performance criteria selection bars
If you would like to revisit and rebalance your portfolio less frequently (e.g., on a quarterly or yearly basis), you can adjust the Mid and Long-Term Performance bars accordingly.
If your objective is to invest in stocks with forecasted high yearly dividend potential, you can assign a higher weight to the Dividend criterion.
The safety bar assists in selecting stocks with a projected maximum drawdown over the next year lower than that of other stocks, as determined by our ML models.
The bars linearly combine all score fields to align with your desired investment goals.
How are ML Alpha Scores calculated?
Behind each of these scores there are what we refer to as Machine Learning “Meta-Models”. A Meta-Model is composed of more than one ML model “trained” to predict certain targets.
As explained in this article, the “training” is the process by which the internal parameters of a Machine Learning model are adjusted in order to better fit data points from the training data. In our case, supervised ML models are fed with training samples (X-y) from the past where:
“X” is a vector of data, or more commonly known as “features”, including fundamental (e.g. P/E Ratio, Earnings Per Share or Return On Equity) technical (e.g. RSI over the past month, Distance from 5-month Simple Moving Average or ) and contextual (e.g. Sector, Industry, SP-500 RSI over the last month) information of the company at date T.
“y” is the target variable to predict at date T. This is, given a certain input vector “x” at period T, we try to predict a target variable “y” over the next period (e.g. the company return at T + 1 month).
The “training” or “fitting” process happens with the training data points, which belong to the past. ML Alpha Meta-Models are trained on around 400k training samples from 1982 to 2015 comprising a great variety of companies in different market dynamics. The ultimate goal is that the prediction capacity achieved with the training data is maintained when new market data is available, i.e. from 2016 onwards and kept in the future. This will in practice, be a very challenging task due to the noisy and ever-evolving nature of the financial markets.
Moreover, if this fitting process is not done carefully one may encounter the challenge of overfitting. Overfitting occurs when a Machine Learning model memorizes the training data too well, including irrelevant details and noise. This can happen in a couple of ways. First, if the model is too complex for the amount of data available, it can start to find patterns in the noise rather than the underlying trends. Second, even with a good model, training for too long can lead to overfitting. This is because the model hasn’t learned to generalize, but it has simply “memorized” the specific examples it was trained on. In the context of financial predictions, an overfitted model might predict perfectly for the companies in the training data, but fail considerably when trying to predict the returns of new companies ultimately yielding very poor results.
Now that we better understand the concept of “training” we are ready to learn more details about how the Meta-Models and ultimately the ML Alpha Scores are obtained:
Short Term Score: This score is based on the prediction of various ML models trained to predict its risk-adjusted return potential over the next 2-Week and 1-Month periods respectively relative to the rest of the companies. As such, this score can be interpreted as the strength of the signals for a given company’s stock price to perform well in the short term relative to the rest of the companies.
Mid Term Score: This score is based on the prediction of various ML models trained to predict its risk-adjusted return potential over the next 1-Quarter and 1-Year periods relative to the rest of the companies. As such, this score can be interpreted as the strength of the signals for a given company’s stock price to perform well in the mid term relative to the rest of the companies.
Long Term Score: This score is based on the prediction of various ML models trained to predict its risk-adjusted return potential over the next 1-Year and 3-Year relative to the rest of the companies. As such, this score can be interpreted as the strength of the signals for a given company’s stock price to perform well in the long term relative to the rest of the companies.
Dividend Score: This score is based on the prediction of various ML models trained to predict its dividend yield potential over the next year relative to the rest of the companies. As such, this score can be interpreted as the strength of the signals for a given company to pay out a high dividend yield over the next year relative to the rest of the companies.
Safety: This score is based on the prediction of various ML models analysing the available company’s data and trained to predict its potential maximum drawdown over the next year and relative to the rest of the companies. As such, this score can be interpreted as the strength of the signals for a given company to not suffer from sharp and/or extended price loss periods over the next year relative to the rest of the companies.
And what data do our Meta-Models use for the predictions?
Each of our ML models composing a meta-model is fed with a variable number of input variables, ranging from a few dozens up to hundreds of them. The input variables include a mix of fundamental, technical and contextual information. A non-exhaustive list of included parameters is provided here:
Fundamental features: Earnings Per Share, Price to Earning Ratio, Earnings Yield, Price to Book Ratio, Dividend Yield, Return on Equity, Debt Equity Ratio, Cash Per Share, Net Debt to EBITDA, Debt to Assets, Return On Assets, Company Equity Multiplier or Enterprise Value Over EBITDA.
Technical features: Relative distances from Simple Moving Averages and All-Time high, Relative Strength Index (RSI), Stochastic Oscillators, MACD, ATR or ADX over various periods. It also includes past performance indicators such as Returns, Alpha, Beta, Sharpe and Sortino Ratios over various periods.
Contextual features: industry, sector, SPY returns over different periods, stock correlation with respect to SPY over different periods, interest rates or price of oil and gold.
The above is a non-exhaustive list that may vary between models and improve over time as further we further develop our data science pipelines and Meta-Models.
During the training process the ML models have access to all these variables to work out multivariate and complex relationships that allow them to predict probabilities with greater accuracy. However, the final trained models do not necessarily give the same weight to all the input variables/information. As it could be expected, we observed that models trained on short-term targets weight technical parameters considerably more than fundamental parameters for their predictions contrary to the models trained for mid to long term predictions (a quarter or a year from now)
All variables fed to the models are “relativised” to the training history period and with respect to all the companies present during the training period. This means that for example, the EPS of company “X” is transformed to a value between 0 and 1 relative to all the EPS of all companies during the training period. This transformation allows to :
The variables used in the models are adjusted to fit within a standard distribution range, typically between 0 and 1, or alternatively, between -1 and 1. This adjustment is necessary for many machine learning models to function effectively
Filter extremely high and/or low values from the dataset due to lack of quality in the input data
Additionally, the historical evolution of the variables is also available to the ML models. This means that the ML model is not only fed with the current relative EPS of company “X” but also its growth over a certain number of periods.
And how do I know if these models work?
It’s important for investors to understand that there are no guarantees in the market, and past performance doesn’t ensure future results. However, certain strategies backed by statistical evidence may have a higher probability of success over time. At ML Alpha we
In order to increase the chances of future success each of our Meta-Models follows a carefully crafted “validation” process. The validation is performed in 2 steps:
1. Statistical Validation
This step involves assessing the statistical relationship between the Meta-Model scores (predictions generated by our Meta-Models) and the actual targets (real-world outcomes of the target metric) using data that the models have never seen before. In our case this data spans from 2016 until the present. We perform a rigorous examination of how closely the predictions generated by our models align with the actual outcomes observed in the market analyzing various statistical metrics:
Correlation coefficients, root mean squared errors (RMSE) and tail-weighted RMSE between Scores and Targets,
Mean target metric performance of top and bottom 10, 20, 50, 100 and 500 scores.
These statistical metrics can gauge the reliability and accuracy of our models when used to predict the target metrics. They are a crucial step in determining whether the models are robust and trustworthy enough to inform investment decisions. However, it’s important to note that while statistical validation provides valuable insights, it doesn’t guarantee future success, as market conditions can change unpredictably.
The statistical performance of the Meta-Models behind ML Alpha as of April 2024 are reported in the next 3 tables:
| Metric name | corr_mla | corr_random | rmse_mla | rmse_random | custom_rmse_mla | custom_rmse_random | start_date | end_date | nb_points |
|---|---|---|---|---|---|---|---|---|---|
| shortTermValueScore0 | 0.0402 | 0.0018 | 0.3999 | 0.4079 | 0.5101 | 0.5198 | 2016-01-17 | 2024-03-03 | 442737 |
| shortTermValueScore1 | 0.0485 | 0.0005 | 0.3982 | 0.4081 | 0.5069 | 0.5199 | 2016-01-17 | 2024-02-18 | 439723 |
| midTermValueScore | 0.0562 | -0.0019 | 0.3966 | 0.4086 | 0.5051 | 0.521 | 2016-01-17 | 2023-12-10 | 427492 |
| longTermValueScore | 0.0412 | -0.0008 | 0.3997 | 0.4084 | 0.5127 | 0.5206 | 2016-01-17 | 2023-03-19 | 382093 |
| safetyScore | 0.5905 | -0.0013 | 0.2612 | 0.4085 | 0.2643 | 0.5211 | 2016-01-17 | 2023-03-19 | 383826 |
| dividendScore | 0.6753 | 0.0012 | 0.2313 | 0.4057 | 0.2071 | 0.5186 | 2016-01-17 | 2023-08-06 | 375391 |
Table 1: Correlation coefficients, Root Mean Squared Errors (RMSE) and tail-weighted RMSE between Scores and Targets. ML Alpha Scores (mla) Vs. Random selection (random)
| metric name | target_metric | mean_perf_top_10_mla | mean_perf_top_10_random | mean_perf_top_20_mla | mean_perf_top_20_random | mean_perf_top_50_mla | mean_perf_top_50_random | mean_perf_top_100_mla | mean_perf_top_100_random | mean_perf_top_500_mla | mean_perf_top_500_random | start_date | end_date | nb_points |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| safetyScore | 1Y_max_drawdown | -0.1795 | -0.3301 | -0.182 | -0.3304 | -0.1934 | -0.3337 | -0.2034 | -0.3342 | -0.2329 | -0.3356 | 2016-01-17 | 2023-03-19 | 383826 |
| shortTermValueScore0 | 2W_pct_change | 0.0129 | 0.0019 | 0.0161 | 0.0026 | 0.0104 | 0.0023 | 0.0092 | 0.0026 | 0.0064 | 0.0033 | 2016-01-17 | 2024-03-03 | 442737 |
| shortTermValueScore1 | 1M_pct_change | 0.0314 | 0.0119 | 0.0317 | 0.0073 | 0.0224 | 0.0085 | 0.0188 | 0.0095 | 0.0145 | 0.009 | 2016-01-17 | 2024-02-18 | 439723 |
| midTermValueScore | 1Q_pct_change | 0.1171 | 0.0241 | 0.0903 | 0.023 | 0.0641 | 0.0239 | 0.0524 | 0.0241 | 0.0359 | 0.024 | 2016-01-17 | 2023-12-10 | 427492 |
| longTermValueScore | 1Y_pct_change | 0.2955 | 0.0967 | 0.2874 | 0.0854 | 0.223 | 0.0846 | 0.175 | 0.086 | 0.1122 | 0.0841 | 2016-01-17 | 2023-03-19 | 382093 |
| dividendScore | forecasted_dividendYield_1y | 4.2475 | 0.4638 | 5.2927 | 0.9229 | 7.5841 | 0.8981 | 6.2121 | 7.4328 | 1.727 | 10.9498 | 2016-01-17 | 2023-08-06 | 375391 |
| metric name | target_metric | mean_perf_bottom_10_mla | mean_perf_bottom_10_random | mean_perf_bottom_20_mla | mean_perf_bottom_20_random | mean_perf_bottom_50_mla | mean_perf_bottom_50_random | mean_perf_bottom_100_mla | mean_perf_bottom_100_random | mean_perf_bottom_500_mla | mean_perf_bottom_500_random | start_date | end_date | nb_points |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| shortTermValueScore0 | 2W_pct_change | -0.0147 | 0.0027 | -0.0114 | 0.0018 | -0.008 | 0.003 | -0.0065 | 0.0032 | -0.0007 | 0.0034 | 2016-01-17 | 2024-03-03 | 442737 |
| shortTermValueScore1 | 1M_pct_change | -0.0278 | 0.0069 | -0.0185 | 0.0071 | -0.0118 | 0.0081 | -0.0086 | 0.0089 | 0.0013 | 0.0091 | 2016-01-17 | 2024-02-18 | 439723 |
| midTermValueScore | 1Q_pct_change | -0.0248 | 0.0306 | -0.0162 | 0.0282 | -0.0155 | 0.026 | -0.0117 | 0.026 | 0.0083 | 0.0253 | 2016-01-17 | 2023-12-10 | 427492 |
| longTermValueScore | 1Y_pct_change | -0.0191 | 0.0809 | -0.0019 | 0.0772 | 0.0147 | 0.0819 | 0.0241 | 0.0824 | 0.0534 | 0.0865 | 2016-01-17 | 2023-03-19 | 382093 |
| safetyScore | 1Y_max_drawdown | -0.6494 | -0.3314 | -0.6271 | -0.3328 | -0.5919 | -0.3339 | -0.5633 | -0.3347 | -0.4732 | -0.3342 | 2016-01-17 | 2023-03-19 | 383826 |
| dividendScore | forecasted_dividendYield_1y | 0.0904 | 0.571 | 0.136 | 0.7129 | 0.1075 | 0.8127 | 0.0672 | 0.6417 | 3.3503 | 7.9262 | 2016-01-17 | 2023-08-06 | 375391 |
Table 3: Mean target metric performance of bottom 10, 20, 50, 100 and 500 scores. ML Alpha Scores (mla) Vs. Random selection (random)
To the best of our knowledge these metrics certify and quantify the edge that ML Alpha Scores offers to our customers for smarter decision-making. Our ML Alpha Scores have a clear positive correlation (with enough distance from 0) with the actual targets and exhibit a consistent mean performance largely superior to random stock selection.
2. Backtesting Validation
This step involves testing the predictive capabilities of the Meta-Models alongside an investment strategy using historical data that the models have never seen before. Essentially, it’s a simulation of how the Meta-Model would have performed if it was used to make investment decisions in the past following a certain investment strategy.
The investment strategy tested is what we call a simple periodic rebalance strategy: this involves setting predetermined time intervals or “periods”, such as monthly or quarterly, to reassess the portfolio’s composition and adjust it back to its original allocation percentages. Both at the first composition and at each of the subsequent recomposition times the number of stocks is fixed to “n” and all stocks have equal weight in the portfolio. The “n” selected stocks are the ones with top “n” Scores predicted by the model at recomposition time.
Note that the backtesting of this strategy starting at a given date may be affected by luck. What if the strategy is started a couple of weeks after? For this reason we launch a Monte Carlo analysis that involves simulating the backtesting process multiple times, each time starting the simulation at a different point in time within the historical data. By doing so, we generate a distribution of potential outcomes, taking into account the variability that may arise from different starting points (as it will be the case for different ML Alpha users). This helps assess the robustness of the AI Scores-powered periodic rebalance investment strategy and provides insights into its performance under various market conditions. Additionally, it allows us to quantify the level of uncertainty associated with the strategy’s historical performance and helps manage expectations regarding future results.
The figure below simulates 100 users following a monthly rebalance strategy selecting the Top 10 Short Term Scores starting a different dates. For the sake of visual clarity it assumes that, despite, the different starting dates all users had an investment capital of 10k$ on the 01/04/2016 The simulation also assumes all gains, including dividends, are reinvested continuously and doesn’t factor in trading fees.
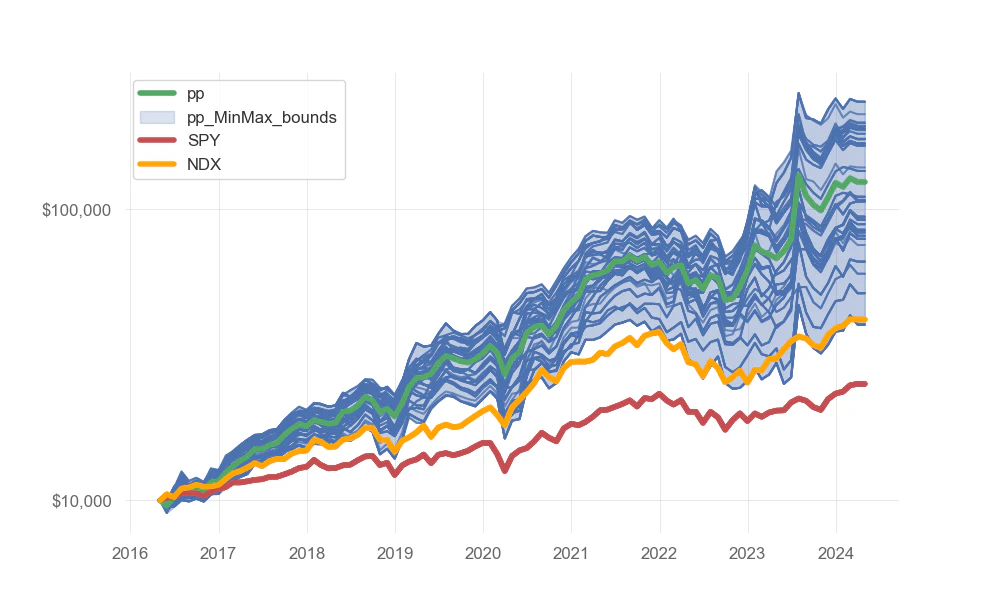
Through this rigorous validation process, we gain confidence in the Meta-Models’ predictive capabilities and the effectiveness of the chosen investment strategy.
Thanks a lot for reading this article, as always we really value our customers/readers feedback. You can request features of anything on our Feedback Page. You can get started with ML Alpha for free here.